
こんにちは、中山( @k1nakayama ) です。
この記事は、AWS LambdaとServerless Advent Calendar 2022の21日目の記事です。
今回は先日行われたre:Invent 2022にて、新機能として発表されたAmazon EventBridge Pipesについて紹介いたします。
- Amazon EventBridge Pipesについて知りたい方
- DynamoDB StreamsやSQSから、イベントデータを他のサービスに渡すためだけにLambdaを書いている方
- コーディング量を減らし、出来るだけコアロジックの開発に専念したい方
Amazon EventBridge Pipesとは
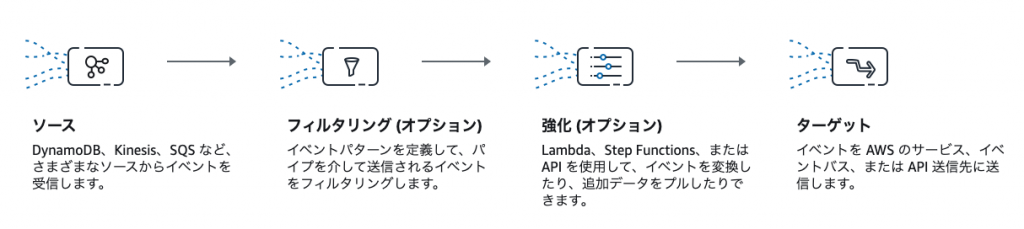
EventBridge Pipesは、これまでポーリングを行うことによってイベントデータを取得していた、DynamoDB StreamsやKinesis Data Streams、SQSなどのイベントソースからデータをポーリングして取得し、CloudWatch Logs、EventBridge EventBus、Step Functions、Redshiftクラスター等様々なAWSサービスにデータを受け渡す事ができるサービスです。また、イベントソースから受け取ったデータをフィルタリングしたり、LambdaやStepFunctions等を使用して加工を加えたり、ターゲットに渡すデータの形を変換することができます。
これまでDynamoDB StreamsやKinesis Data Streams、SQSなどから受け取ったデータを、Step Functionsに渡してステートマシンを起動したり、EventBusにデータを送信するなどのためにわざわざLambdaを作成していた方も多いのではないかと思いますが、これらのLambdaを書かずにEventBridge Pipesに置き換えるだけでデータの受け渡しを行えるようになります。
データソース
入力データとして選択できるデータソースは、現在のところ下記のとおりです。
- Kinesis Data Streams
- SQS
- DynamoDB Streams
- Amazon MQ
- セルフマネージド Apache Kafka
- Amazon Managed Streaming for Apache Kafka(MSK)
ターゲット
データの送信先となるターゲットは、現在のところ下記のとおりです。
- API Gateway
- API Destinations
- AWS Lambda
- CloudWatch Logs
- ECSクラスター
- EventBridge EventBus
- Firehose Stream
- Inspector assessment
- Kinesis Data Streams
- Redshiftクラスター
- SageMaker Pipeline
- SNSトピック
- SQSキュー
- Step Functions
- AWS Batch Job Queue
ユースケース
具体的にどのようなユースケースで使えるかを考えてみました。
Step Functionsの起動
何らかのイベントをトリガーにStep Functionsにデータを渡し起動することはよく使われます。
この時、イベント発生元のLambdaなどから直接Step Functionsをキックすると、同期的な呼び出しとなり何らかの事情によりStep Functionsの起動が失敗した場合、それらのエラーハンドリングやリトライなどを考えて実装しなければなりません。この対処として、一般的な手法としては、イベントをSQSにメッセージを送信してキューに入れ、そのメッセージを別途Lambdaで取り出し、Step Functionsを起動することで、リトライなどについても対処しやすくなりました。
この際に、Step Functionsを起動するために作成していたLambdaは、EventBridge Pipesを使用することでコードを書かずに実装できるようになります。
マイクロサービス間のイベントルーティング
マイクロサービス間で他のマイクロサービスで発生したイベントに基づいて、自マイクロサービスでのアクションを行うためにイベントルーティングを活用し実装しているケースもあるかと思います。
このような時にとても使えるのが、EventBridgeのEventBusとルールの機能です。
自マイクロサービス内で発生したイベントを、EventBusに送信しておくことで、それらのイベントを必要に応じて受け取り別のマイクロサービスによりイベントを基に処理を実装することができ、各コンポーネントが疎結合になり、機能拡張が行いやすくなります。
このときに、例えばDynamoDB Streamsから全てのイベントをEventBusに送るためには、これまでLambdaを各マイクロサービス内で作成し、EventBusへの送信を行わなければなりませんでした。
EventBridge Pipesを使うことで、DynamoDB StreamsからのデータをEventBusへ送信することが、Lambdaを作成することなく実装できます。
この仕組は3factor appでも欠かせない機能となるかと思います。
Slack通知
システム運用において、様々な場面でSlackへの通知を活用している方も多いのではないでしょうか?CloudWatch Alarm等の一部の通知については、AWS ChatbotとSNSを組み合わせることでSlackへの通知が容易になっており、これらの対応が出来ているものについては、既にLambdaを作成することなく通知出来るようになっています。しかし、AWS Chatbotが対応しているものはわずかでしかなく、最も通知を行いたい、自らの構築するシステムが好きな形で通知を行うものについては対応していません。
これを行うために、Slackへの通知を行うためのLambdaを作成していたりしませんか?
EventBridgeにはAPI Destinationという機能が2021年3月に提供開始されており、この機能を使用することで、様々なAPIへのリクエストを、認証やレートリミットなどを含めて簡単に管理することが出来ます。EventBridge PipesはこのAPI Destinationもターゲットに含んでいるため、通知を行いたいイベントをSQSに入れたり、DynamoDBの特定のアイテムのステータスが変わったことを検知した時などに、Lambdaを作成することなくSlackへの通知を行うことが出来るようになります。
イベントのロギング
例えばDynamoDBに対して、特定のアイテムのステータスが通常とは異なる値に変わった場合、それらのイベントの動きをロギングしておきたいとした場合、これまでは、そのアイテムを操作する可能性のあるLambdaそれぞれで、ステータスが記録するべき値になった際にロギングするように処理をそれぞれで実装するか、DynamoDB Streamsでイベントを取得しLambdaでロギングをするなどの処理が必要でした。
これらについても、DynamoDB Streamsをイベントソースとして、ステータスでフィルタリングし、CloudWatch Logsをターゲットとして設定することで、Lambdaを書くことなくロギングを行うことができます。
Opensearch Serviceへのデータ同期
DynamoDBをデータストアとして主に使用しているサーバーレスアプリケーションの場合、データの検索をしたい場合などによく用いられるアーキテクチャとして、DynamoDB Streamsからデータ更新イベントをLambdaで受け取り、Opensearch Service(旧Elasticsearch Service)に入れて、検索時はOpensearch Serviceで検索を行うパターンがあります。
これについても、LambdaではDynamoDB Streamsから受け取ったデータを、ただOpensearch Serviceに受け渡すだけしか行っていません。
なので、今回EventBridge Pipesの出番かも!と思ったのですが、残念ながらターゲットにOpensearch Serviceは選択できませんでした。しかし、ターゲットとしてKinesis Firehoseが選択できるので、EventBridge Pipes → Kinesis Firehose → Opensearch Serviceという形で受け渡すことで、こちらもLambdaレスで同期を行うことが可能になりそうです。
ETL処理
EventBridge Pipesにはエンリッチというオプション機能があり、データソースから受け取ったデータをただターゲットに受け渡すだけではなく、受け渡し前にLambdaやStep Functions等を使用して加工を加えるプロセスを入れることが可能です。そして、EventBridge PipesのターゲットにはRedshiftクラスターも選択できます。S3にデータがアップロードされたら、そのイベントをSQSに通知し、EventBridge Pipesで必要に応じて加工を行い、Redshiftにデータをロードするという流れを、少なくともデータをロードする処理のためだけにLambdaを書くことはせずに実装が行なえます。(※後述しますが、実装できるはずですが、まだ私は実現できていません)
権限分離
ターゲットにLambdaも選択できるのは一見無意味に感じました。しかし、これまでは例えばDynamoDB StreamsをLambdaで直接イベントを受け取ろうとした場合、Lambdaの実行ロールにはdynamodb:DescribeStream等のいくつかのDynamoDBからイベントを受け取るための権限を与える必要がありました。このようにイベントソースからLambdaが直接イベントを取得しようとすると、責任境界が入り混じってしまいます。
EventBridge Pipesはイベントソースへのポーリング処理を行うことと、ターゲットへのリクエストを行うための権限に限定したIAM Roleを保持して処理を行います。これにより、イベントを受け取って処理するLambdaがあった場合、そのLambdaにはイベントソースへの権限は不要であり、ただEventBridge Pipesから渡されたイベントを処理することに専念出来ます。
このように明確な権限分離を行って管理を行うこともしやすくなるため、ターゲットにLambdaを選択出来ることは、無意味ではありません。
上記以外にも、多くのターゲットが選択できるため、まだまだユースケースは広がるかと思います。
実際に使ってみた
この記事を書く前に、いくつかのユースケースを想定して実際に設定を行い、どれぐらい簡単に使えるかなどを体験してみました。
実際に使った上での率直な感想としては、エラーハンドリングがほぼ行えず、挙動が不安定に感じることや、マネージメントコンソール上での操作は少し触っただけでもいくつかバグらしき挙動が見られる、という感じで機能に対する期待値が大きい分、現状の体験には残念に感じる点がありました。
具体的な内容は下記の通りです。
エラーハンドリングが出来ない
使っていた中で全ての問題に共通して感じたのがコレです。イベントソースからイベントが入ってきた履歴やイベントの内容をフィルタリング、加工、ターゲットに受け渡すデータの変換などが、どこでどうなっているのか全く分からず、ログ出力も行われないため、AppSyncが出た当初のリゾルバーの入出力が分からず難儀した頃を思い出しました。CloudWatchメトリクスに5分毎のイベント数や成功、失敗等の数が見れるので、それを頼りに設定を操作していくしか出来ません。
ロギング代わりに、ターゲットをCloudWatch Logsにしておくことで、多少状況を理解しやすくはなりますが、これも後述の通り安定せず難しい状況でした。
処理結果が不安定?
これは実際のところ原因が不明なため、一概には言えないのですが、前述の通りデバッグ代わりにターゲットをCloudWatch Logsにして処理結果を出力していました。不安定な挙動を感じたのは、DynamoDB Streamsをイベントソースとしていたときですが、CloudWatch Logsに出力がされた!と思ったあとに、DynamoDB上でアイテムの更新を何度か行ってみると、ログ出力がされるイベントとされないイベントがあり、設定を更新していないにも関わらず挙動が安定しないという状況がありました。
マネージメントコンソールでの操作にバグがある
マネージメントコンソールでの操作にはいくつかバグが見つかっており、例えばイベントソースをDynamoDB Streamsに設定しターゲット等も設定した後、パイプを作成したら、それ以降イベントソースを変更することが出来ませんでした。(フォームが無効化されていて操作できない)
また、ターゲットに渡すイベントの形を変換するトランスフォーマーの欄について、一度設定してパイプを更新すると、トランスフォーマーを初期化(設定をなしにする)ことが出来ません。
また、トランスフォーマーの部分ではイベントのJSONを動的に指定する記述が行えますが、下記のようにJSONオブジェクトを指定した場合でも、保存されたテンプレートをAWS CLIで確認すると勝手にダブルクオーテーションが付いてしまっており、EventBridge EventBusへの入力時に正しいJSON形式でないためエラーとなっていたことがありました。
トランスフォーマーで記述したもの
{
"dynamodb": <$.dynamodb>
}実際に登録されていたテンプレート(AWS CLIで確認)
{
"dynamodb": "<$.dynamodb>"
}上記はマネージメントコンソール上から更新すると、必ずダブルクオーテーションが付いてしまったため、CLIでupdate-pipeを実行しテンプレートを修正することで、意図した設定に更新することが出来ました。
また、テンプレートを初期化することも、CLIから下記のように実行することで行えました。
$ aws pipes update-pipe --name pipe-name --role-arn arn:aws:iam::123456789012:role/service-role/Amazon_EventBridge_Pipe_role --target-parameters '{"InputTemplate": ""}'RedshiftへのSQLステートメント内に動的パラメータを挿入できない
S3へのCSVデータのputObjectイベントをSQSに通知し、そのイベントをEventBridge Pipesで受け取って、CSVファイル名をCOPY文に渡す形でデータのロードを行いたいと思いました。
この処理には何点か問題があり、EventBridge Pipesは動きを見るに、SQSから同時に複数件のメッセージを受信した場合でも、1件ずつ処理に渡されているように見えるのですが(入力イベントはRecordsの内側のJSONオブジェクトだけが1件ずつ入ってくる)、S3からSQSにイベントを送る部分も同時に複数オブジェクトの通知を1メッセージとして送ることがあるため、SQSのBodyにはRecordsから含まれています。この時、トランスフォーマーのテンプレート内や、SQLステートメントを記述する部分で、動的パラメータとして<$.body.Records[0].s3.object.key>のように配列に対するインデックスを指定して記載しようとすると無効な記述としてエラーとなり指定できませんでした。そのため、この部分は複数入ってくる可能性も考慮してエンリッチなどでどうにかしないといけないかもしれません。
しかし、問題はまだ続き、SQLステートメントにてCOPY文を定義する際、from句には引用符で囲った形で読み込み対象のオブジェクトキーを指定する必要がありますが、動的パラメータはテンプレート内で引用符で囲われた中に記載されていると動的パラメータとして処理されません。
copy category
from 's3://pipes-test-ap-northeast-1/<$.key>'
iam_role 'arn:aws:iam::123456789012:role/service-role/AmazonRedshiftRole'
csv;現状では、トランスフォーマーなどで動的パラメータを含めた形で文字列を定義することができなさそうなため、上記の例で言えばs3://pipes-test-ap-northeast-1/<$.key>に相当する文字列全体をエンリッチで出力して、それをSQLステートメントの指定時にfrom <$.s3key>のような形で指定するしかなさそうです。折角Lambdaを書かなくてよくなるはずが、s3のキーを指定するためにLambdaで調整をしないといけないのは本末転倒な感じがするので、このあたりは改善されることを期待したいですね。。
まとめ
EventBridge Pipesについての紹介と、ユースケース、現状の問題点などを紹介いたしました。
出たばかりでベータリリースをすっ飛ばして正式リリースされたからか、過去にここまで問題が多いサービスあったっけ?と思うぐらい問題がありそうですが、これらはEventBridge Pipesのサービスチームが頑張って早期に改善してくれることを祈ります。
これらの問題が改善されて、期待通り使えるようになると、間違いなくサーバーレス開発においては欠かせない機能となるかと思います。
今後の展開に期待していきたいと思います。
