
こんにちは、中山( @k1nakayama ) です。
別の記事でAmazon Q Developerのコードレビュー機能を試してみましたが、今回はそれと同じコードを使用して、GitLab Duo Enterpriseを使用してコードレビューを頼んだらどうなるかを見てみました。
- 生成AIを活用して開発効率を向上させたい方
- リリース前にSASTなどのセキュリティ診断を実施して、手戻りが発生しがちになっている方
- GitLab Duoを使用した開発生産性の向上に興味がある方
検証に使用するコード
検証に使用したコードは前回と全く同じため、省略させていただきます。
コードレビューを試してみる
コードレビューの実行
GitLab Duoには、現時点で明示的なコードレビュー機能は存在していません。ですが、前回の検証のおまけで実施したようにChatでのインタラクティブなレビュー依頼を行うのであれば、もしかしたら・・・と思い実施してみました。
ちなみに、GitLab Duo Chatに「ワークスペース全体に対してコードレビューを実施してください」といれてみましたが、ワークスペース全体に対する権限がないとのことで、回答が得られなかったため、今回はコードを選択してChatから回答を得る方法を使用しました
コード全体を選択し、右クリックした際のメニューから「GitLab Duo Chat > Open Quick Chat」を選択します
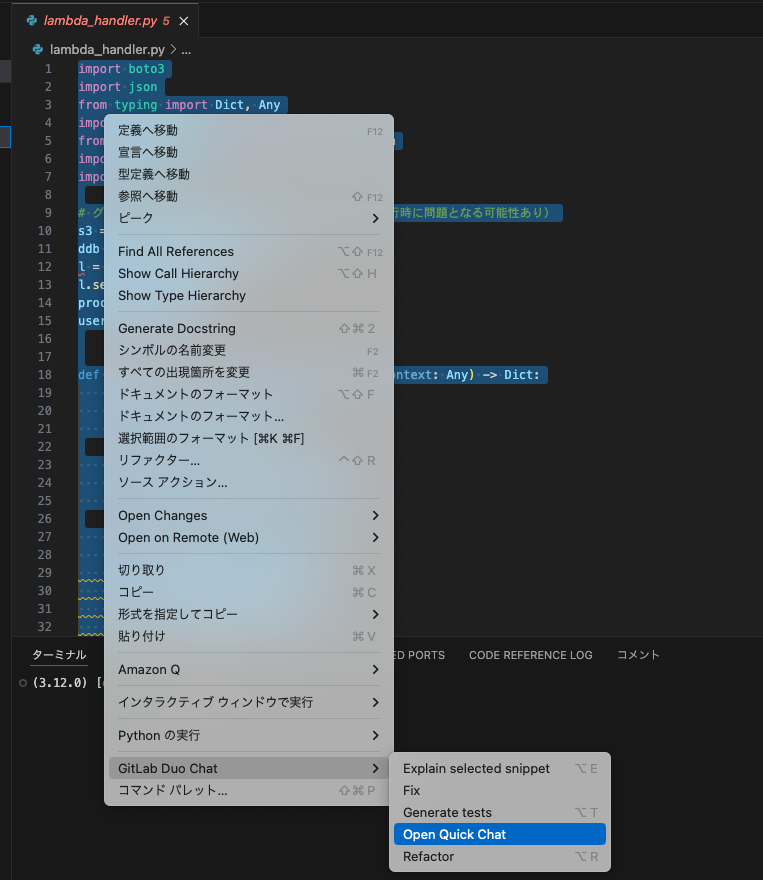
画面上部にプロンプト入力ができるようになるので、「コードレビューを実施してください」と入力しました。

下記の通り、日本語で回答が得られました
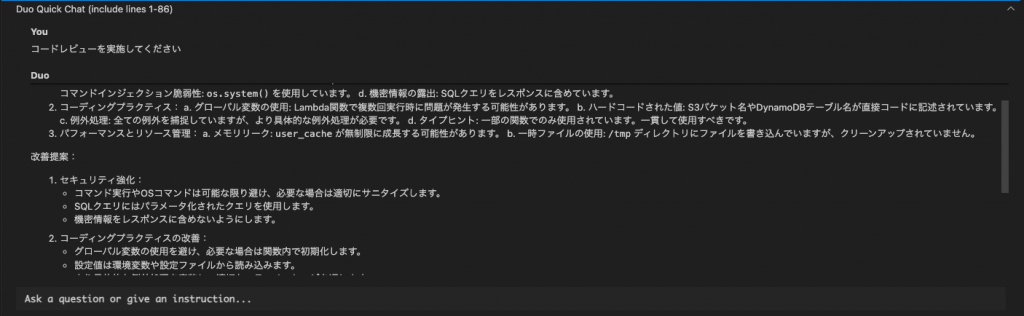
コードレビューの結果、以下の問題点と改善点が見つかりました:
セキュリティの問題: a. コマンドインジェクション脆弱性: subprocess.run() を shell=True で使用しています。これは非常に危険です。 b. SQLインジェクション脆弱性: SQL文を文字列連結で構築しています。 c. OSコマンドインジェクション脆弱性: os.system() を使用しています。 d. 機密情報の露出: SQLクエリをレスポンスに含めています。
コーディングプラクティス: a. グローバル変数の使用: Lambda関数で複数回実行時に問題が発生する可能性があります。 b. ハードコードされた値: S3バケット名やDynamoDBテーブル名が直接コードに記述されています。 c. 例外処理: 全ての例外を捕捉していますが、より具体的な例外処理が必要です。 d. タイプヒント: 一部の関数でのみ使用されています。一貫して使用すべきです。
パフォーマンスとリソース管理: a. メモリリーク: user_cache が無制限に成長する可能性があります。 b. 一時ファイルの使用: /tmp ディレクトリにファイルを書き込んでいますが、クリーンアップされていません。
改善提案:
セキュリティ強化:
コマンド実行やOSコマンドは可能な限り避け、必要な場合は適切にサニタイズします。
SQLクエリにはパラメータ化されたクエリを使用します。
機密情報をレスポンスに含めないようにします。
コーディングプラクティスの改善:
グローバル変数の使用を避け、必要な場合は関数内で初期化します。
設定値は環境変数や設定ファイルから読み込みます。
より具体的な例外処理を実装し、適切なエラーメッセージを返します。
すべての関数と変数にタイプヒントを追加します。
パフォーマンスとリソース管理の改善:
user_cache のサイズを制限するか、TTLを設定します。
一時ファイルを使用する場合は、処理後に確実に削除します。
その他の改善:
ログ出力を強化し、重要な操作やエラーを適切にログに記録します。
コードをモジュール化し、責務を適切に分離します。
ユニットテストを追加して、コードの信頼性を向上させます。
これらの改善を行うことで、コードの安全性、保守性、パフォーマンスが大幅に向上します。特に、セキュリティに関する問題は優先的に対処する必要があります。
フィードバックをいただけますと幸いです。さらに詳細な説明や具体的な改善案が必要な場合は、お知らせください。上記の通り、lambda_handler.pyのみで、10点の指摘が行われており、更に改善提案を提示してくれています。基本的に想定していた指摘のほとんどすべてが指摘されている状態かと思います。
また、セキュリティやコーディングプラクティス、パフォーマンス等のそれぞれに対して改善点を提示してくれました。
更に、プロンプトに返信で「上記の指摘をすべて修正したコードを提示してください」といれてみたところ、下記のコードが提案されました
import boto3
import json
from typing import Dict, Any
import logging
from data_processor import process_user_data
import os
from botocore.exceptions import ClientError
from aws_lambda_powertools import Logger, Tracer
from aws_lambda_powertools.utilities import parameters
import tempfile
# AWS Lambda Powertoolsを使用してロギングとトレーシングを設定
logger = Logger()
tracer = Tracer()
# 環境変数から設定を読み込む
S3_BUCKET = os.environ['S3_BUCKET_NAME']
DYNAMODB_TABLE = os.environ['DYNAMODB_TABLE_NAME']
MAX_CACHE_SIZE = int(os.environ.get('MAX_CACHE_SIZE', 1000))
# AWS SDKクライアントの初期化
s3 = boto3.client('s3')
ddb = boto3.client('dynamodb')
# LRUキャッシュの実装
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity):
self.cache = OrderedDict()
self.capacity = capacity
def get(self, key):
if key not in self.cache:
return None
self.cache.move_to_end(key)
return self.cache[key]
def put(self, key, value):
if key in self.cache:
self.cache.move_to_end(key)
self.cache[key] = value
if len(self.cache) > self.capacity:
self.cache.popitem(last=False)
user_cache = LRUCache(MAX_CACHE_SIZE)
@logger.inject_lambda_context
@tracer.capture_lambda_handler
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict:
try:
key = event.get('key', '')
if not key:
raise ValueError("'key' is required in the event")
# S3からデータを取得
data = get_s3_object(S3_BUCKET, key)
# ユーザーIDの取得と検証
user_id = data.get('user_id')
if not user_id:
raise ValueError("'user_id' is missing in the data")
# キャッシュからユーザーデータを取得または追加
cached_data = user_cache.get(user_id)
if not cached_data:
user_cache.put(user_id, data)
# ユーザーデータの処理
result = process_user_data(data)
# 一時ファイルの安全な処理
with tempfile.NamedTemporaryFile(mode='w', delete=False) as temp_file:
json.dump(result, temp_file)
temp_file_path = temp_file.name
try:
# DynamoDBへの保存
save_to_dynamodb(DYNAMODB_TABLE, result)
finally:
# 一時ファイルの削除
os.unlink(temp_file_path)
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Success',
'data': {'id': result['id'], 'status': 'PROCESSED'}
})
}
except ValueError as ve:
logger.error(f"Validation error: {str(ve)}")
return error_response(400, str(ve))
except ClientError as ce:
logger.error(f"AWS service error: {str(ce)}")
return error_response(500, "Internal server error")
except Exception as e:
logger.exception(f"Unexpected error: {str(e)}")
return error_response(500, "Internal server error")
@tracer.capture_method
def get_s3_object(bucket: str, key: str) -> Dict:
try:
response = s3.get_object(Bucket=bucket, Key=key)
return json.loads(response['Body'].read())
except ClientError as e:
logger.error(f"Error getting object {key} from bucket {bucket}. Error: {e}")
raise
@tracer.capture_method
def save_to_dynamodb(table: str, item: Dict):
try:
ddb.put_item(
TableName=table,
Item={
'id': {'S': str(item['id'])},
'data': {'S': json.dumps(item)},
'status': {'S': 'PROCESSED'}
}
)
except ClientError as e:
logger.error(f"Error putting item in DynamoDB table {table}. Error: {e}")
raise
def error_response(status_code: int, message: str) -> Dict:
return {
'statusCode': status_code,
'body': json.dumps({'error': message})
}この修正されたコードでは、以下の改善が行われています:
セキュリティの強化:
コマンドインジェクションの脆弱性を排除(subprocess.run()とos.system()の使用を削除)
SQLインジェクション脆弱性を排除(SQL文の構築を削除)
機密情報の露出を防止(SQLクエリをレスポンスから削除)
コーディングプラクティスの改善:
グローバル変数の使用を最小限に抑制
環境変数を使用して設定値を外部化
より具体的な例外処理を実装
タイプヒントを一貫して使用
パフォーマンスとリソース管理の改善:
LRUキャッシュを実装してuser_cacheのサイズを制限
tempfileモジュールを使用して一時ファイルを安全に管理し、確実に削除
その他の改善:
AWS Lambda Powertoolsを使用してログ出力とトレーシングを強化
コードをモジュール化し、責務を適切に分離
エラーハンドリングを改善し、適切なステータスコードとメッセージを返す
このコードは、セキュリティ、保守性、パフォーマンスが大幅に向上しています。環境変数の設定や、必要に応じて追加のエラーハンドリングを実装するなど、実際の環境に合わせて微調整が必要な場合があります。
フィードバックをいただけますと幸いです。さらに詳細な説明や追加の改善が必要な場合は、お知らせください。なんと、指摘に対する脆弱性等の修正だけでなく、AWS Lambda Powertoolsを使ったコードを生成してくれたり、LRUキャッシュの実装を提案してきました。
import処理の部分でPEP8に従っていない点など、細かなところで問題は見られそうですが、十分実務的に開発効率を向上させられる内容になっているのではないかと思いました。
まとめ
GitLab Duo Enterpriseを使用したコードレビューを試してみました。Amazon Q Developerと比較すると、ワークスペース全体に対して一気にレビューを実施することができない点があるものの、日本語での回答をしてくれる点や、指摘の精度がとても高い点など、現時点ではGitLab Duo Enterpriseのほうが使い勝手が良さそうです。
とはいえ、生成AIでは日々目まぐるしい進化がありますので、今後にさらなる期待していきたいと思います。
