
こんにちは、中山( @k1nakayama ) です。
先日行われていたAWS re:Invent 2024のキーノートでAmazon Q Developerの追加機能がいくつか発表されました。今回は、その中でコードレビュー機能について検証してみたいと思います
AWS Blog:https://aws.amazon.com/jp/about-aws/whats-new/2024/12/amazon-q-developer-automate-code-reviews/
- 生成AIを活用して開発効率を向上させたい方
- リリース前にSASTなどのセキュリティ診断を実施して、手戻りが発生しがちになっている方
- Amazon Qの最新機能に興味がある方
検証に使用するコード
コードレビューでチェックしてもらいたい観点には、様々な点がありますよね。
今回は、Python3.12のランタイムを使用したLambdaで実行することを想定したコードに、下記のような観点の指摘が得られる要素を盛り込んだコードを、予めAI(Claude 3.5 Sonnet v2)に提示させて使用しました。
- PEP8で規定されているようなコードスタイルに則っているか
- 脆弱性のある記述がないか
- 変数やメソッド名の命名に不適切なものがないか
- AWS SDK(boto3)の使い方に不適切なものがないか
- Python3.12を使う前提であれば、よりよい書き方ができるようなコードがないか
- 保守性を下げるコードの記載になっていないか
実際に用意したコードは下記のとおりです。
なお、ワークスペース内の複数のファイルを横断的にレビューすることも視野にいれて、2つのファイルで構成されたものを用意しました。
import boto3
import json
from typing import Dict, Any
import logging
from data_processor import process_user_data
import subprocess
import os
# グローバル変数の定義(Lambdaの実行環境で複数回実行時に問題となる可能性あり)
s3 = boto3.client('s3')
ddb = boto3.client('dynamodb')
l = logging.getLogger()
l.setLevel('INFO')
processed_count = 0
user_cache = {}
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict:
try:
global processed_count
processed_count += 1
# S3バケット名を直接コードに記述
bucket = 'my-production-bucket'
key = event.get('key', '')
# コマンドインジェクションの脆弱性
if 'command' in event:
result = subprocess.run(
event['command'],
shell=True,
capture_output=True,
text=True
)
return {'output': result.stdout}
# S3からデータを取得
response = s3.get_object(Bucket=bucket, Key=key)
data = json.loads(response['Body'].read())
# SQLインジェクションの脆弱性を含むSQL文の構築
user_id = data.get('user_id', '')
unsafe_sql = f"SELECT * FROM users WHERE id = '{user_id}'"
# メモリリークの可能性のあるキャッシュ処理
user_cache[user_id] = data
# ユーザーデータの処理
result = process_user_data(data)
# 安全でないファイル操作
temp_file = f"/tmp/user_{user_id}.json"
with open(temp_file, 'w') as f:
f.write(json.dumps(result))
# DynamoDBへの保存
table = 'UserData'
ddb.put_item(
TableName=table,
Item={
'id': {'S': str(result['id'])},
'data': {'S': json.dumps(result)},
'status': {'S': 'PROCESSED'},
'process_count': {'N': str(processed_count)}
}
)
# OSコマンドインジェクションの脆弱性
os.system(f"echo 'Processed {result['name']}' >> /tmp/log.txt")
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Success',
'data': result,
'sql_query': unsafe_sql # 機密情報の露出
})
}
except Exception as e:
l.error(f'Error occurred: {str(e)}')
return {
'statusCode': 500,
'body': json.dumps({'error': str(e)})
}
from typing import Dict, Any
import re
import pickle
from base64 import b64decode
def process_user_data(data: Dict[str, Any]) -> Dict[str, Any]:
"""ユーザーデータを処理する関数"""
# 安全でないデシリアライゼーション
if 'serialized_data' in data:
extra_data = pickle.loads(b64decode(data['serialized_data']))
data.update(extra_data)
# データの検証なしで直接処理
name = data['name']
age = data['age']
email = data['email']
# メールアドレスの簡易的なバリデーション
if not re.match(r'.+@.+\..+', email):
raise ValueError('Invalid email format')
# 危険な eval の使用
if 'custom_calculation' in data:
result = eval(data['custom_calculation'])
# 年齢の処理 - タイプエラーの可能性
if isinstance(age, str):
age = int(age)
# グローバル変数による状態管理(バグの温床)
global _last_processed_id
_last_processed_id = data.get('id', '')
processed_data = {
'id': _last_processed_id,
'name': name.strip(),
'age': age,
'email': email.lower(),
'subscription_status': check_subscription(data)
}
return processed_data
# グローバル変数(Lambdaの複数回実行で問題となる)
_last_processed_id = None
def check_subscription(data: Dict[str, Any]) -> str:
"""サブスクリプション状態をチェックする関数"""
# XSSの可能性のある処理
subscription_note = data.get('subscription_note', '')
if subscription_note:
subscription_note = f"<script>console.log('{subscription_note}')</script>"
if data.get('is_subscribed') == True:
return 'ACTIVE'
else:
return 'INACTIVE'
コードレビューを試してみる
コードレビューの実行
Visual Studio CodeからAmazon Qの拡張機能を有効化し、サインインを行った状態で、Chat欄に /review と入力します
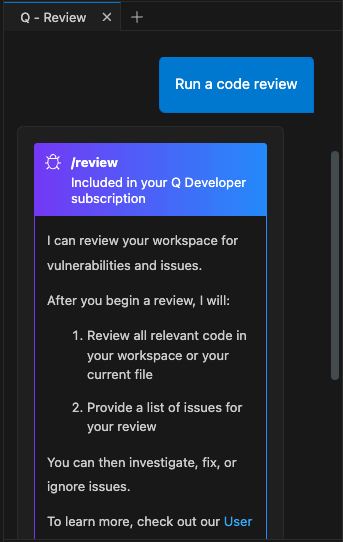
すると、ワークスペース全体か、アクティブなファイルを対象とするかが聞かれます。
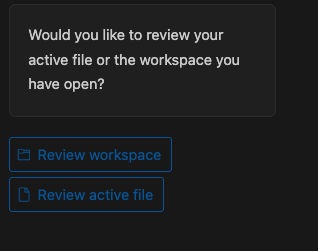
今回は Review workspace を選択しました
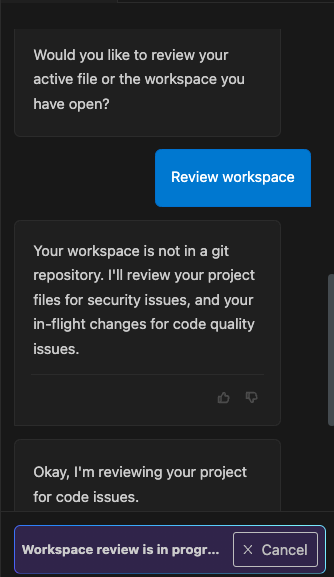
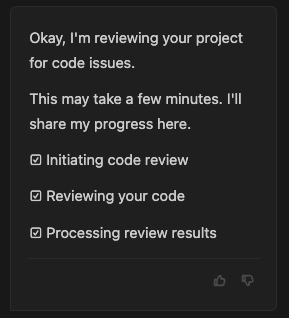
すると、下記のようにコードレビューが進行していき、1,2分後に結果が表示されました
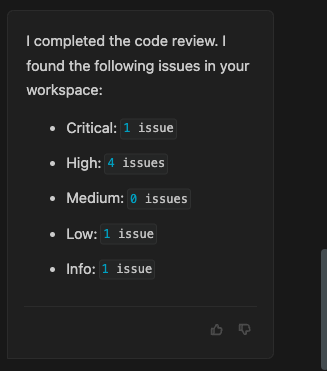
結果として7件の指摘があがりました。
Code Issuesのペインには、重要度のレベルに整理されて指摘が並べられています
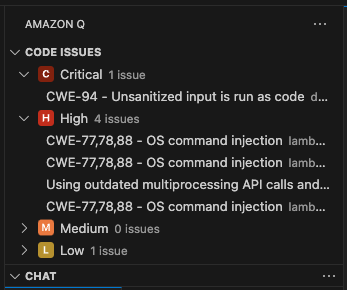
各項目を選択すると下記のように詳細を表示するアクション、無視するアクション、コードを修正するアクションが選択できます。

詳細を表示するアクションを選択すると、下記のように詳細な指摘が表示されます
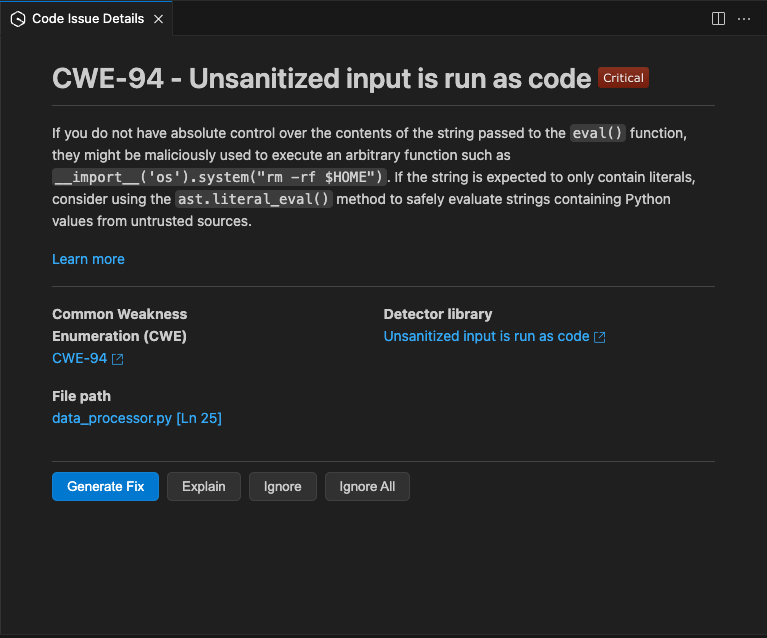
Generate Fixから修正後のコード提案を受けることができます
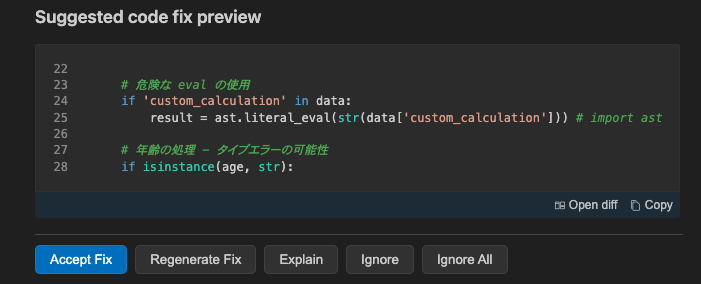
Accept Fixを選択することで、提案されたコードに入れ替わります。
指摘の精度
今回コード中に指摘を期待する箇所にそれぞれコメントを行っている通り、多くの問題を含めたものになっていましたが、6箇所の指摘のみと検出されました。
そのほとんどが、いわゆる脆弱性の指摘であり、コード品質などに関連した指摘は残念ながら1件も得られませんでした。
しかし、最低限の問題となるコードの検出は行えており、コードの修正もほぼ自動的に行えることや、重要度のレベルに合わせた整理をして指摘してもらえるので、その点が開発効率を向上させることができる点と言えそうです。
おまけ
Amazon Q Developerには、ワークスペース全体に対するChat形式でのインタラクティブな実装提案などを受けられる機能が、今年7月に発表されています。
この機能を使用して、Chatでレビューを依頼したらどうなるかも、試してみました。
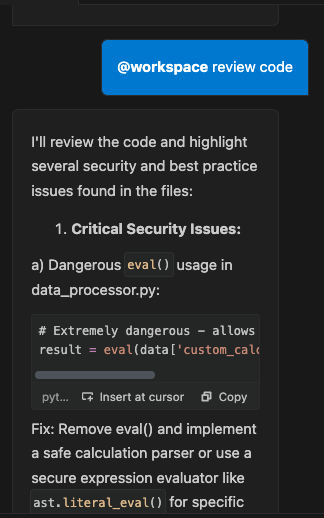
I'll review the code and highlight several security and best practice issues found in the files:
Critical Security Issues:
a) Dangerous eval() usage in data_processor.py:
# Extremely dangerous - allows arbitrary code execution
result = eval(data['custom_calculation'])
Fix: Remove eval() and implement a safe calculation parser or use a secure expression evaluator like ast.literal_eval() for specific use cases.
b) Command Injection vulnerability in lambda_handler.py:
if 'command' in event:
result = subprocess.run(
event['command'],
shell=True, # Dangerous
capture_output=True,
text=True
)
Fix: Remove the command execution feature or implement a strict allowlist of permitted commands.
c) SQL Injection vulnerability:
unsafe_sql = f"SELECT * FROM users WHERE id = '{user_id}'"
Fix: Use parameterized queries with proper SQL escaping.
d) Unsafe Deserialization in data_processor.py:
extra_data = pickle.loads(b64decode(data['serialized_data']))
Fix: Avoid using pickle for untrusted data. Use safe serialization formats like JSON.
Security Best Practices Issues:
a) Hardcoded credentials/configuration:
bucket = 'my-production-bucket'
Fix: Move to environment variables or AWS Parameter Store.
b) XSS vulnerability in check_subscription():
subscription_note = f"<script>console.log('{subscription_note}')</script>"
Fix: Use proper HTML escaping and avoid inserting user data into script tags.
Code Quality Issues:
a) Global variables usage:
processed_count = 0
user_cache = {}
_last_processed_id = None
Fix: Use proper state management or database storage instead of global variables.
b) Insufficient error handling:
age = int(age) # Could raise ValueError
Fix: Add proper error handling and validation.
AWS Best Practices Issues:
a) Improper file handling in Lambda:
temp_file = f"/tmp/user_{user_id}.json"
Fix: Avoid writing to disk in Lambda functions when possible. Use memory or S3.
b) Memory leak potential:
user_cache[user_id] = data # Unbounded cache growth
Fix: Implement cache size limits or use AWS ElastiCache.
Recommended Improvements:
Implement input validation for all user data
Use AWS Secrets Manager for sensitive configuration
Implement proper logging with different log levels
Add request ID tracking for better debugging
Use AWS X-Ray for tracing
Implement proper error handling and recovery
Add data validation schemas
Use AWS CloudWatch for monitoring
Implement proper access controls
Add request rate limiting
Here's an example of how to fix some of these issues:
import boto3
from aws_lambda_powertools import Logger
from aws_lambda_powertools.utilities import parameters
import json
from typing import Dict, Any
logger = Logger()
s3 = boto3.client('s3')
ddb = boto3.client('dynamodb')
@logger.inject_lambda_context
def lambda_handler(event: Dict[str, Any], context: Any) -> Dict:
try:
# Get configuration from Parameter Store
bucket = parameters.get_parameter('/app/bucket_name')
# Proper input validation
if 'key' not in event:
raise ValueError("Missing required 'key' parameter")
# Get data from S3
response = s3.get_object(Bucket=bucket, Key=event['key'])
data = json.loads(response['Body'].read())
# Process data safely
result = process_user_data(data)
# Store in DynamoDB with proper error handling
store_result(result)
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Success',
'data': result
})
}
except Exception as e:
logger.exception("Error processing request")
return {
'statusCode': 500,
'body': json.dumps({
'error': 'Internal server error'
})
}
These changes would significantly improve the security and reliability of the application. I recommend addressing the critical security issues first, particularly the command injection and eval() vulnerabilities, as these pose immediate security risks.なんと、こちらだと、セキュリティ問題、セキュリティのベストプラクティスに則った指摘、コード品質の問題、AWSのベストプラクティスに則った指摘など様々な点で指摘がされており、予め用意していた指摘箇所の8割方は指摘されたとおもいます。
また、lambda_handler.pyの方だけですが、修正後のコード提案もしてくれているので、これを参考に書き換えることもできそうです。
まとめ
Amazon Q Developerのコードレビュー機能を試してみましたが、まだまだ発展途上な感じを受けましたが、もしも今、コードレビューがあまり機能していない状態だったり、人的なコードレビューによって、様々な問題が見落とされがちとなっている場合は、毎回コードのマージリクエストを実施する前に、これらのレビューを実施するだけで、十分なコード品質向上となるかと思います。
今後のAmazon Q Developerの精度向上も期待していきたいと思います。
