
こんにちは、中山( @k1nakayama ) です。
AWS Lambda Function URLsが発表されたことで、API Gatewayを設けずともLambdaをコールすることが出来るようになってワイワイやっていますが、今回はそんなLambdaを使った処理の中でも、比較的よく使われるだろう、DynamoDBからデータをリスト出力するような処理について考えてみたいと思います。
- DynamoDB上の大量のデータを対象としたクエリ処理を行おうとしている方
- UXを考慮して少しでも早いレスポンスが行えるAPIバックエンドの開発をしたい方
- 効率的なクエリ処理について学びたい方
DynamoDBを使用したクエリ方法
そもそもDynamoDB内から、ある条件に合致するアイテムのリストを取得するためのクエリ方法として、どのような方法があるでしょうか?
- Queryオペレーションにより、HASHキーを指定
- Queryオペレーションにより、HASHキーとRANGEキーを指定
- Scanオペレーションにより、フィルター条件を指定
- Scanオペレーションにより、フィルター条件とセグメントを指定
細かな条件を加えると上記の他にもパターンはありますが、大まかに分けると上記の4種類のクエリ方法になるかと思います。
いきなり唐突な質問を投げかける形になりますが、皆さんは上記の4つ目の「Scanオペレーションにより、フィルター条件とセグメントを指定」についてご存知でしたか?実は私はこのScan時にセグメントに分けてクエリすることが出来ることをつい最近知りました。
そして、今回の検証をしようと思ったキッカケもそこにあり、普段ある種毛嫌いしていたScanオペレーションもシチュエーションによっては使えるかもと思い、試してみたものでした。
パラレルスキャン
ここまできても、何やら全然分からないかと思うので、私が今回新たに知ったScan時のセグメント指定について、簡単に紹介いたします。
DynamoDBのScanオペレーションでは、通常フィルター条件を指定する程度で実行していたかと思いますが、実はScanオペレーション時のパラメータとして、SegmentやTotalSegmentsというものが存在していました。( boto3 dynamodb.client.scan)
response = table.scan(
FilterExpression=Key('category').eq(category) & Key(
'date').between(start_date, end_date),
Segment=segment,
TotalSegments=total_segments
)上記のように、SegmentとTotalSegmentsを指定することで、Scanオペレーションを複数のセグメントに分割して処理することができる仕組みになっています。このため、セグメントを分けて並列実行することで、分割した数分だけ実行時間を短縮出来る、といった発想です。
ここで焦点となりそうなのは、セグメントを分けてそれぞれを実行する方法になるかと思います。並列実行出来る必要があり、その結果を収集して結合することが出来なければ意味がないことを考えると、複数スレッドを使うか、複数プロセスで並列実行する方法になるかと思います。
今回試した際に使ったのはPythonを使用しており、残念ながらPythonでは実質複数スレッドでの実行は行えないようですので、Pythonで実行する場合は、複数プロセスで並列処理することになるかと思います。
実はこのパラレルスキャンについては、GSIを使用したQueryオペレーションと比較するまでもなく、やはり遅いことが分かりました。そのため、GSIを設けることが出来る場合は普通にQueryオペレーションをしたほうが良いという結論に至りました。
パラレルクエリ
上記の解説では、既に結論を出してしまっており、検証が終わったかに思えたのですが、この過程で新たにもう1つの仮設が浮かびました。
Queryオペレーションを複数セグメントに分けて、並列実行したら高速にクエリ出来るのではないか?
これを検証していくために、まずはパラレルクエリを行うための方法について検討しました。
Queryオペレーションは、HASHキーを完全一致で指定することが必要ですが、RANGEキーについては、範囲指定や前方一致での指定が可能です。今回はこのRANGEキーを使って並列にクエリを実行していく方法を検証していくことにしました。
パラレルクエリの検証
前提(検証条件)
今回DynamoDBに格納されているデータは、下記のようなトランザクションデータをイメージしたテーブルです。
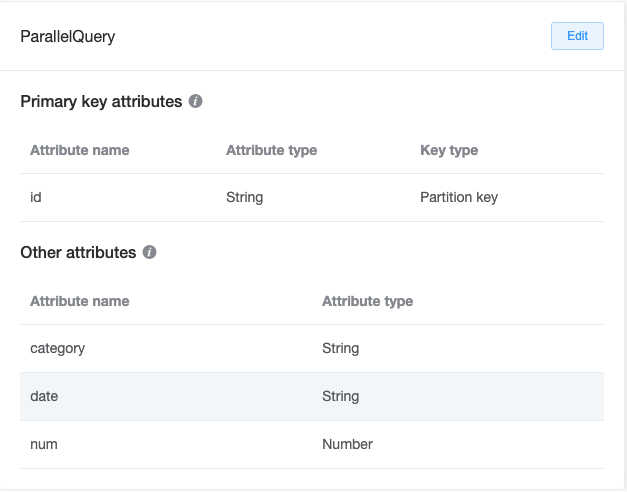
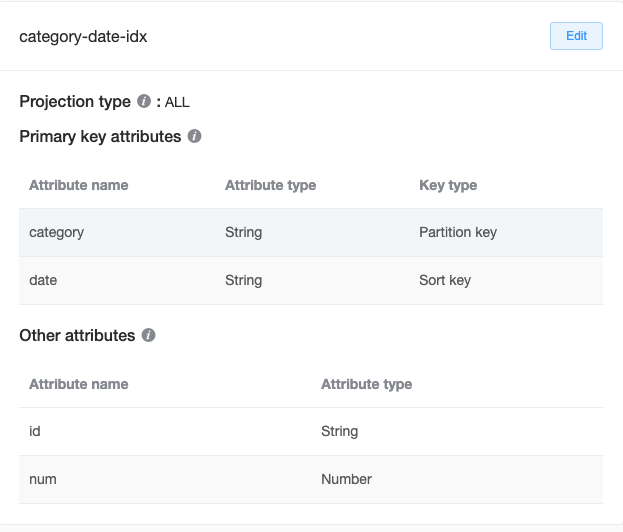
上記のようなテーブル構造で、データを予め100万件いれてあり、Categoryは6種類に分けて入れたため、1カテゴリあたり平均17万件前後入っているイメージです。ちなみに、日付は2022年1月から12月までの日付で、データ投入時の手間を削減する都合上、各月1日〜28日までの日付でランダムとなっています。
今回はこのテーブルから下記の条件でアイテムをクエリすることを検証します。
- categoryがbooksと一致
- dateが2022/01/01〜2022/03/28の範囲
- 結果はdateで並び替えを行った状態のリストを生成し、件数を返す
- 実行はLambdaから行うため、コールドスタートを無視する意味で初回の実行分は結果に含めない
- 実行時メモリ容量は最大の10240MB(10GB)
通常のクエリ(シーケンシャルクエリ)
通常のクエリでは、今回の条件に対し、category-date-idxのGSIインデックスを使用した形で、category=’books’、dateが’2020/01/01’〜’2020/03/28’までの範囲指定でクエリする処理とします。dateでの並び替えはもとからdateをRANGEキー(Sortキー)に指定したインデックスを使用することで、自動的にdateで並び替えられた結果が返ります。
実際のコードは下記の通り
import boto3
from boto3.dynamodb.conditions import Key
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table("ParallelQuery")
start_date = '2022/01/01'
end_date = '2022/03/28'
category = 'books'
def seq_query_with_index():
def query(ExclusiveStartKey=None):
params = {
"IndexName": 'category-date-idx',
"KeyConditionExpression": Key('category').eq(category) & Key(
'date').between(start_date, end_date),
"ReturnConsumedCapacity": "TOTAL"
}
if ExclusiveStartKey is not None:
params['ExclusiveStartKey'] = ExclusiveStartKey
return table.query(**params)
response = query()
data = response['Items']
consumed_rcu = response['ConsumedCapacity']['CapacityUnits']
while 'LastEvaluatedKey' in response:
response = query(response['LastEvaluatedKey'])
data.extend(response['Items'])
consumed_rcu += response['ConsumedCapacity']['CapacityUnits']
return (data, consumed_rcu)
def lambda_handler(event, context):
data, rcu = seq_query_with_index()
print("RCU: "+ str(rcu))
return {
'statusCode': 200,
'body': len(data)
}実行した結果は、10回の実行結果の平均で、2073.667ms(約2秒ちょっと)掛かり、41,631件の結果を抽出出来ました。
並列実行によるクエリ(パラレルクエリ)
続いては、今回の検証の狙いであるパラレルクエリを行います。
実行時の考え方として、シーケンシャルクエリと同様に、category-date-idxのGSIインデックスを使用した形で、category=’books’を指定することまでは同じです。
パラレルクエリでは、dateが’2022/01/0′, ‘2022/01/1’, ‘2022/01/2’, ‘2022/02/0’・・・といった形で日付の最後の値以外をプレフィクスとした値で始まる日付を条件に、全部で9分割して、それぞれ別プロセスを発行し並列実行を行った後、それらの結果を結合します。
この場合、dateの値は実行が終わったプロセスごとに順番が入れ替わってしまうため、結合した後のリストに対して、dateを並び替える処理が必要となります。
実際のコードは下記の通り
import boto3
import multiprocessing
from boto3.dynamodb.conditions import Key
query_date = ['2022/01/0', '2022/01/1', '2022/01/2', '2022/02/0',
'2022/02/1', '2022/02/2', '2022/03/0', '2022/03/1', '2022/03/2']
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table("ParallelQuery")
category = 'books'
total_segments = len(query_date)
datas = []
def para_query(conn, segment):
def query(segment,ExclusiveStartKey=None):
params = {
"IndexName": 'category-date-idx',
"KeyConditionExpression": Key('category').eq(category) & Key(
'date').begins_with(query_date[segment]),
"ReturnConsumedCapacity": "TOTAL"
}
if ExclusiveStartKey is not None:
params['ExclusiveStartKey'] = ExclusiveStartKey
return table.query(**params)
response = query(segment)
data = response['Items']
consumed_rcu = response['ConsumedCapacity']['CapacityUnits']
while 'LastEvaluatedKey' in response:
response = query(segment,response['LastEvaluatedKey'])
data.extend(response['Items'])
consumed_rcu += response['ConsumedCapacity']['CapacityUnits']
print('Segment ' + str(segment) + ' returned ' + str(len(data)) + ' items')
conn.send((data, consumed_rcu))
conn.close()
def lambda_handler(event, context):
process_list = []
parent_connection_list = []
for i in range(total_segments):
parent_conn, child_conn = multiprocessing.Pipe()
parent_connection_list.append(parent_conn)
process_list.append(multiprocessing.Process(
target=para_query, args=(child_conn, i)))
for process in process_list:
process.start()
data = []
rcu = 0
for parent_connection in parent_connection_list:
d, consumed_rcu = parent_connection.recv()
data.extend(d)
rcu += consumed_rcu
sorted_data = sorted(data, key=lambda x:x['date'])
print("RCU: " + str(rcu))
return {
'statusCode': 200,
'body': len(sorted_data)
}マルチプロセスの扱い方などは、ここでは省かせていただきますが、下記のように並列処理が行えていることが分かります。
Segment 0 returned 4383 items
Segment 6 returned 4488 items
Segment 3 returned 4506 items
Segment 1 returned 4982 items
Segment 4 returned 4945 items
Segment 2 returned 4554 items
Segment 7 returned 4886 items
Segment 5 returned 4445 items
Segment 8 returned 4442 items実行した結果は、10回の実行結果の平均で、477.627ms(約0.5秒)掛かり、41,631件の結果を抽出出来ました。
検証結果
検証を行った結果は下記の通りです。
| 回数 | シーケンシャルクエリ | パラレルクエリ |
| 1回目 | 2036.1ms | 439.43ms |
| 2回目 | 2077.12ms | 457.55ms |
| 3回目 | 2103.53ms | 503.26ms |
| 4回目 | 2116.37ms | 498.43ms |
| 5回目 | 2006.78ms | 497.47ms |
| 6回目 | 2087.02ms | 460.2ms |
| 7回目 | 2022.17ms | 475.21ms |
| 8回目 | 2071.48ms | 488ms |
| 9回目 | 2091.91ms | 457.97ms |
| 10回目 | 2124.19ms | 498.75ms |
| 平均 | 2073.667ms | 477.627ms |
| 標準偏差 | 37.8587184ms | 21.4368305ms |
| 消費RCU | 368RCU | 368.5RCU |
ちなみに、パラレルクエリのdateを月毎に分ける形で合計3分割にした場合約900ms、毎日の日付ごとに分ける形の合計84分割にした場合約670msという結果でした。
また、シーケンシャルクエリはLambdaのメモリ割り当てを1024MB(1GB)まで下げると3200msと大幅に遅くなりましたが、2048MB(2GB)だと2100msとほぼ変わらない時間で処理出来ることが分かりました。
消費されるRCUは0.5RCUだけ違うもののほぼ同じ消費キャパシティとなっており、処理時間は約4.4倍ですが、メモリ量が5分の1なので、ほぼ同じぐらいのコストで4倍以上のレイテンシーを下げたレスポンスが行えるようになることが分かりました。
まとめ
今回DynamoDB上の大量データに対するクエリ方法を検証してみました。
ちょっとした工夫をするだけで、大きくレイテンシーを下げることができる事がわかりました。
しかも、今回の実行したコード自体は、クエリ処理を行う上で、要件毎に大きな違いはなく、大部分を使い回すことが出来そうです。
ちなみに、今回対象パーティションに対するデータ数が17万件ほどのデータに対してクエリを行いましたが、100分の1の1,700件ほどのデータに対して同様の処理を実行したところ、シーケンシャルクエリは約30ms、パラレルクエリは約80msと大幅にレイテンシーが高くなってしまいました。そのため一概にパラレルクエリを行う実装をすることが良いわけでは無いことも分かりましたが、予めデータボリュームが分かっていて、今回のような適度な分割が行えるものであれば、実装する価値があるのではないでしょうか?
また、冒頭で今回の検証の対象外としてしまったパラレルスキャンについても、今回のようにスキーマ構造が具体的に分かっていて、対象クエリ用にGSIを用意出来る場合にはパラレルクエリが検討出来ますが、様々な構造をもつエンティティを横断的に抽出する場合や、スキーマ構造が不明なテーブルに対してクエリを行う場合には、有効な手段の1つになるかもしれません。
